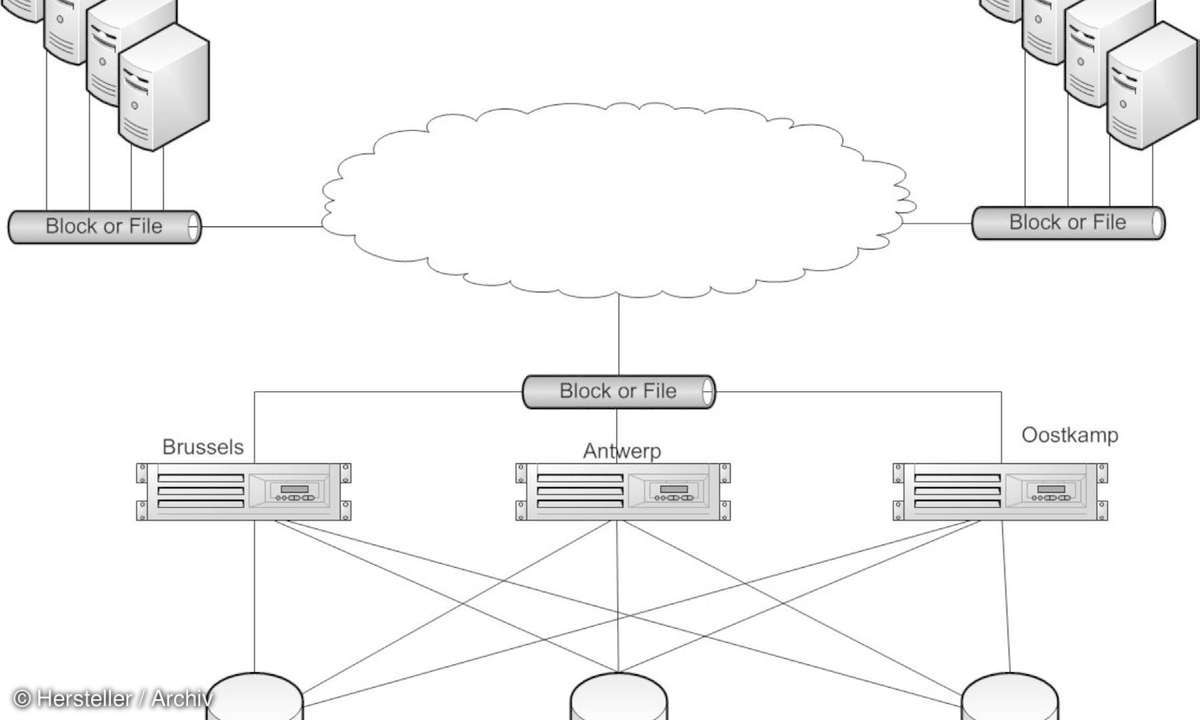
Metrocluster im Unternehmen
Sogenannte Metrocluster sind ein probates Mittel, um die Hochverfügbarkeit der IT-Systeme selbst im Katastrophenfall zu gewährleisten. Diese schalten beim Ausfall eines Rechenzentrums einfach auf ein zweites um.

Redundanz ist der Schlu?ssel zur Hochverfu?gbarkeit. Das gilt auch fu?r den Extremfall, in dem man ein ganzes Rechenzentrum vor Stromausfällen und Katastrophen schu?tzt. Ein Metrocluster ist im Grunde genommen ein auf zwei oder mehr Standorte auseinander gezogenes lokales Cluster, bei dem ein l...
Redundanz ist der Schlu?ssel zur Hochverfu?gbarkeit. Das gilt auch fu?r den Extremfall, in dem man ein ganzes Rechenzentrum vor Stromausfällen und Katastrophen schu?tzt. Ein Metrocluster ist im Grunde genommen ein auf zwei oder mehr Standorte auseinander gezogenes lokales Cluster, bei dem ein lokal gespiegelter Speicher zum Einsatz kommt.
Ein Metrocluster kann so gestaltet werden, dass kein einziger Point of Failure bestehen bleibt und dass ein einzelner Hardwareausfall noch kein Umschalten zwischen den Sites notwendig macht. Der größte Vorteil eines Metroclusters ist das automatische Umschalten, ohne dass ein Administrator eingreifen muss.
Beim Einsatz einer asynchronen Replikation muss ein Mensch entscheiden, wann und ob umgeschaltet wird. Dies bedingt wiederum einen vorher definierten Notfallplan. Die Automatisierung dieses Prozesses kann dagegen eine durchgängige Uptime fu?r Applikationen garantieren.
Technischer Hintergrund
Pro Standort besteht das Konzept aus einem Storage-Layer, der jeweils lokal hochverfu?gbar ausgelegt ist - jeweils ein Cluster mit zwei Nodes. Dieses Cluster stellt den Festplattenspeicher fu?r die Service-Nodes zur Verfu?gung. Diese spiegeln jeweils ihre Daten zwischen den beiden Standorten, und alle vier Nodes gehören zu einem standortu?bergreifenden 4-Node-Cluster. Ein volles Metrocluster bietet zahlreiche Vorteile:
- Keine Ausfallzeiten wegen Upgrades, weder fu?r Hardware noch Software,
- einfacher Aufbau und Verwaltung,
- vollkommener Schutz aller unternehmenskritischen Daten,
- automatisches und manuelles Failover.
Um ein Metrocluster aufzubauen, sollten zwei Bedingungen erfu?llt sein:
- Die Leitungen zwischen den Rechenzentren mu?ssen sich durch eine sehr niedrige Latenz auszeichnen.
- Die Entfernungen sollten rund 50 Kilometer nicht u?berschreiten, da durch die Entfernung auch die Latenzzeiten steigen und höhere Latenzen die Leistung des Gesamtsystems beeinträchtigen.
In den USA, wo Standorte oft Tausende von Kilometern voneinander entfernt sind, besteht aus diesem Grund in den meisten Fällen u?berhaupt keine technische Möglichkeit, ein Metrocluster einzusetzen und das Konzept ist dort daher kaum bekannt. Die Idee eines Metroclusters orientiert sich an europäischen Gegebenheiten, wo Unternehmen oft mehrere Niederlassungen und Rechenzentren haben, die nur wenige Kilometer voneinander entfernt sind. Hier können viele Unternehmen mit relativ geringen Investitionen die Verfu?gbarkeit ihres Clusters auf ein sehr hohes Niveau heben.
Szenarien eines Systemausfalls
Ein Cluster hat zahlreiche Schwachstellen. Ziel eines Metroclusters ist es, fu?r jeden Schwachpunkt automatische Ru?ckfall-Lösungen bereitzustellen, um negative Auswirkungen auf Applikationen zu vermeiden oder zumindest stark einzuschränken.
Im Folgenden werden sieben Ausfallszenarien und ihre Folgen am Beispiel eines Metroclusters auf Basis des ZFS-Dateisystems dargestellt.
1. Ausfall einer Festplatte: Fällt eine Festplatte aus, hat dies fu?r den operativen Betrieb so gut wie keine Folgen. Der Administrator tauscht die Platte im laufenden Betrieb aus, die Daten der defekten Platte werden einfach wieder synchronisiert.
2. Ausfall wichtiger Komponenten in den Disk-Shelves: Das Multi-Pathing der Storage Nodes sorgt beim Ausfall eines SAS-Kabels, SAS-HBAs oder Expanders dafu?r, dass alle Services ohne Unterbrechung online bleiben. Der Administrator ersetzt die Teile im laufenden Betrieb.
3. Ausfall eines ganzen Disk-Shelves: Die Verteilung der RAIDZ-2-Festplattenverbu?nde werden so zwischen den JBODs verteilt, dass auch ein kompletter JBOD-Ausfall verkraftet wird. Wird ein JBOD nach einem Ausfall wieder zugeschaltet, so werden nur die bis dahin veränderten Daten synchronisiert. Alle Services bleiben so ohne Unterbrechung online, ohne dass kein nennenswerter Einbruch der Performance zu erwarten ist.
4. Ausfall eines Storage-Nodes: Beim Ausfall eines kompletten Servers der Storage-Nodes u?bernimmt ein zweiter Server am selben Standort innerhalb weniger Sekunden die Aufgaben des defekten Servers. Obwohl der I/O-Datenstrom kurzzeitig aussetzt, werden diese Aussetzer nicht an die Anwendungen weitergereicht, da zu jeder Zeit noch der Spiegel zum zweiten Standort vorhanden ist.
5. Ausfall eines Switches, Kabels oder Fibre Channel-HBAs zwischen Storage- Nodes und den oberen Service- Nodes: Auch dieses Szenario wird durch Multi-Pathing der Service Nodes bewältigt. Ein Failover auf das andere Rechenzentrum ist nicht notwendig und die Performance der Applikationen wird nicht merklich beeinträchtigt.
6. Ausfall eines Service-Nodes: Bei einem kompletten Ausfalls eines Service- Nodes kommt es bei der Nutzung von ZFS nur zu einer kurzen, einige Sekunden dauernden Unterbrechung des I/O-Stroms an die Applikationen. Die Umschaltzeit ist abhängig von der Anzahl der Services wie NFS-Shares, CIFS-Shares, iSCSI-Targets. Sie ist dagegen unabhängig von der Datenmenge, da ZFS-Technologie im Gegensatz zu anderen Systemen nie einen kompletten File-System-Check durchfu?hren muss.
Fu?r die Applikationsserver ist diese Umschaltung transparent, im Falle von Fibre-Channel mu?ssen die Applikationsserver vom Betriebssystem einen ALUA-fähigen Multi-Pathing-Treiber mitbringen, was heute oft Standard ist.
Das Cluster wird so konfiguriert, dass die Services immer zuerst auf den lokal benachbarten Node umgezogen werden, um ein Site-Failover nur fu?r den kompletten Ausfall eines Standorts nötig zu machen.
7. Ausfall eines kompletten Standorts: Im schlimmsten anzunehmenden Fall fällt ein kompletter Standort aus. Erst in diesem Fall nutzt das Metrocluster die Redundanz des Rechenzentrums fu?r ein Failover und der zweite Standort u?bernimmt alle Services. Den Anwendungsservern stehen somit alle Dienste zur Verfu?gung, wenn auch nur auf der Hälfte der Service-Nodes, das heißt mit eingeschränkter Performance.
Da in diesem Fall allerdings auch das Spiegeln, Lesen und Schreiben zwischen den Standorten wegfällt, verbessert sich die Latenz, was etwa bei Datenbanken sogar zu besserer Performance fu?hren kann. Geht der ausgefallene Standort wieder online, wird niemals der komplette Datenbestand zuru?ckgespielt, sondern nur alle bisher dahin geänderten Daten.
Ausfall ohne "Split Brain"
Um bei einem einfachen Ausfall der Verbindungen zwischen den Rechenzentren keine undefinierten Zustände, sogenannte "Split Brains" (geteilte Gehirne), zu erhalten, wird ein ZFS-Metrocluster idealerweise wie folgt implementiert:
- Bei undefinierten Zuständen wird nicht auf Verdacht automatisch zwischen den Sites umgeschalten. Services bleiben zuerst dort online, wo sie bisher liefen. Manuelles Eingreifen des Administrators ist mit einem Mausklick natu?rlich möglich.
- Volume-Service-Locking sorgt dafu?r, dass ein einfacher Netzwerkausfall zwischen den Sites auch nur als Netzwerkausfall erkannt wird.
- Ein Cloud-Beacon-Repeater sorgt dafu?r, dass die beiden Standorte gegenseitig den "Herzschlag" des anderen hören und u?ber dessen Zustand informiert sind.
- End-to-End-Pru?fsummen u?ber den gesamten Datenbestand hinweg sorgen dafu?r, dass fehlerhafte Daten automatisch gefunden und mittels der Parität repariert werden können.
- Das Copy-on-Write-Verfahren sorgt dafu?r, dass beim Schreiben neue Daten nicht den alten Datenblock u?berschreiben. Stattdessen wird ein neuer Block zugewiesen und die Metadaten als Referenz des Originals ändern sich, um auf den neuen Block zu verweisen. Auf diese Weise sind Daten in ZFS stets konsistent.
Fazit
Hochverfu?gbare Rechenzentren sind heute das Ru?ckgrat zahlreicher Unternehmen, die hohe Summen in ihre Geschäftstätigkeit investieren. Fu?r alle Unternehmen, die ohnehin zwei Standorte innerhalb von 50 Kilometer Umkreis besitzen oder die Ressourcen in einem von Dienstleistern betriebenen Rechenzentrum in Anspruch nehmen können, ist ein Metrocluster eine geeignete Methode, ihre Systeme unter allen Umständen zugänglich und aktiv zu halten.