Statistische Verfahren
- Grundlagen: Maschinelles Übersetzen
- Übersetzungsverfahren
- Statistische Verfahren
Diese gravierenden Nachteile - Regelexplosion, Inkonsistenzen, hohe Fehlerquoten - entfallen beim zweiten großen Methodenkomplex: den statistischen Verfahren. Sie erleben derzeit einen neuen Aufschwung, nachdem der Vater dieser MÜ-Variante, Peter F. Brown, 1990 im Watson Research Center von IBM er...

Diese gravierenden Nachteile - Regelexplosion, Inkonsistenzen, hohe Fehlerquoten - entfallen beim zweiten großen Methodenkomplex: den statistischen Verfahren. Sie erleben derzeit einen neuen Aufschwung, nachdem der Vater dieser MÜ-Variante, Peter F. Brown, 1990 im Watson Research Center von IBM erste Schritte in diese Richtung unternahm.
Sprachwissenschaftler mit grammatischen Analysen sind hier nicht mehr gefragt. Statt dessen regiert die pure Rechengewalt. Dem Computer werden hier nicht Regeln beigebracht, sondern bestehende Übersetzungen statistisch ausgewertet. Schließlich ist fast jede Phrase und jeder Satz bereits mehrfach übersetzt worden. Es gilt nur, diese Quellen anzuzapfen und auszuwerten.
Das Grundprinzip ist einfach: Vor der eigentlichen Übersetzung analysiert ein Programm einen möglichst großen und breitgefächerten Textkorpus bereits übersetzter, zweisprachiger Texte. Dabei werden Wörter und grammatische Formen in Ausgangs- und Zielsprache einander aufgrund ihrer Häufigkeit und gegenseitigen Nähe zugeordnet.
Beispielsweise kann man zählen, wie oft "ich" neben "ess" im Deutschen und entsprechend "je" neben "mange" im Französischen stehen. So analysiert der Computer Satz für Satz, ohne sich um den Sinn zu kümmern. Irgendwann hat der Rechner genug Material angehäuft, um frische Texte anzugehen, für die es noch keine Übersetzung gibt. Auf Basis der Erfahrungswerte ist der Rechner dann in der Lage, für jede Wortkombination und jeden Satz die wahrscheinlichste Übersetzung zu errechnen.
Auch Mehrdeutigkeiten können bei diesem Ansatz leicht aufgelöst werden. Um etwa das Beispiel "wir treffen uns im Schloss" zu deuten, fahndet das Programm in seiner Datenbank nach Texten, in denen "treffen" und "Schloss" nah beieinanderstehen. Dann durchforstet es die Übersetzungen dieser Texte und findet dort häufig das Wort "castle".
Daher gibt die Maschine "we meet in the castle" und nicht "we meet in the lock" aus. Das Verfahren lebt von der Textmasse: Je mehr Text zur Verfügung steht, umso besser werden die Übersetzungen. Wichtigste Datengrundlage war in früheren Zeiten die Bibel, die in hunderten von Sprachen komplett übersetzt wurde. Doch für bessere Übersetzungen waren noch riesigere Textmengen notwendig.
Google Translate
Heute ist das Internet die wichtigste Quelle, aus denen sich die Sprachstatistiker bedienen. Beste Karten bei der Sammelaktion haben hier Suchmaschinen. Bei Google lagern für viele Sprachpaare Billionen Einträge in den Datenbanken. Angezapft werden besonders gern Transkripte der Vereinten Nationen oder die 23-sprachigen EU-Dokumente. Kein Wunder also, dass sich Google auch auf diesem Gebiet engagiert.
Der Online-Übersetzer Google Translate gilt als das Beste, was derzeit mit statisch-basierten Verfahren möglich ist. Perfektioniert hat das System der deutsche Forscher Franz Josef Och. 57 Sprachen beherrscht sein System bereits. Die Datenbanken für 296 weitere sind schon im Rohbau. Unter ihnen finden sich Exoten wie Sardisch, Westfriesisch oder Zulu.
Mit ihrem Vorstoß stehen Och und Google aber längst nicht alleine da: Forschergruppen rund um den Globus arbeiten in größtenteils universitären Projekten daran, die Entwicklung der statistischen Methoden voranzubringen. Das Projekt EuroMatrix beispielsweise soll ein hybrides System entwickeln, das zwischen den Sprachen aller Mitgliedsstaaten der EU übersetzt.
Um die Projekte fortlaufend zu evaluieren, kommt das 2002 von IBM entwickelte Messverfahren Bleu (Bilingual Evaluation Understudy) zum Einsatz, das mittlerweile standardisiert wurde. Bleu gleicht die maschinellen Ergebnisse mit den Referenztexten relativ zuverlässig auf identische Übersetzungen ab. Daraus errechnet das System einen Wert, der über die Qualität der Übersetzung Aufschluss gibt.
Die aktuellen Zwischenstände der Euromatrix lassen sich im Web verfolgen. Alle bisher erzielten Bleu-Werte machen deutlich, wie stark die statistische MÜ noch von der englischen Sprache und von dem Textfundus abhängt.
Wie regelbasiertes Übersetzen funktioniert - ein einfaches Beispiel
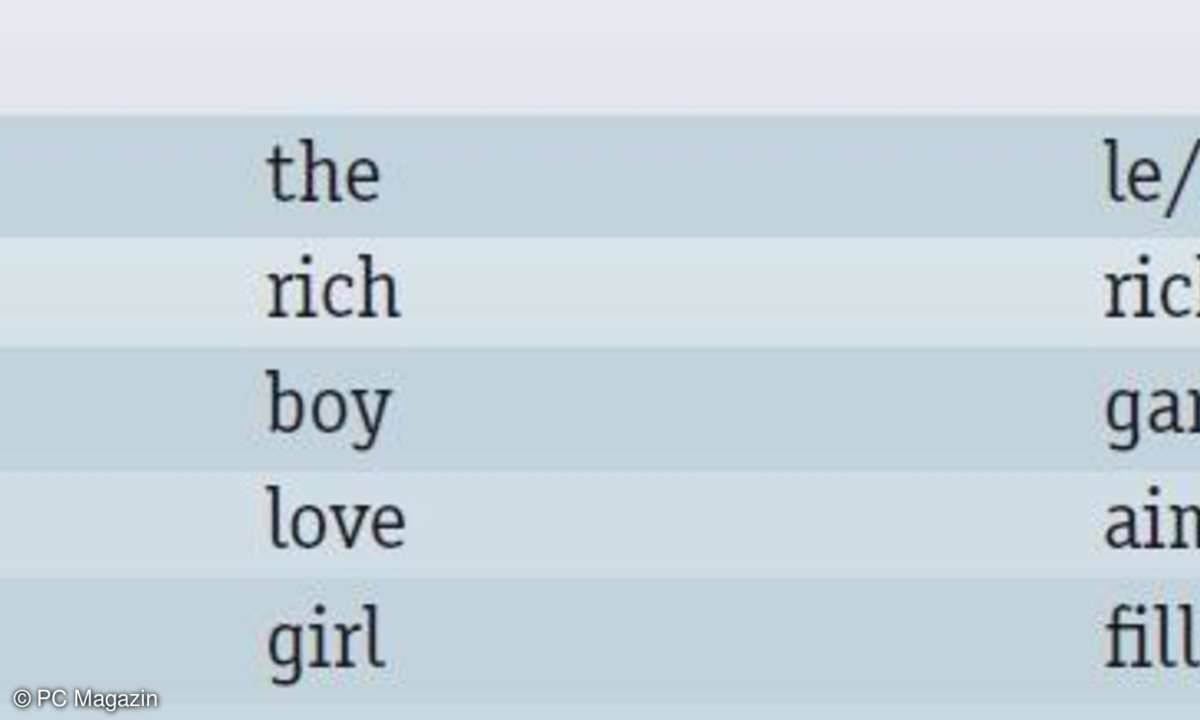
Die Beispielgrafik zeigt links die grammatische Struktur des Satzes "The rich boy loves the girl." Der Baum ist dabei wie folgt zu lesen: Ein Satz S besteht aus einer Nominalphrase Np und einer Verbalphrase Vp (S -> Np Vp).
Eine Nominalphrase besteht aus einem Artikel Art, einem Adjektiv Adj und einem Nomen N und so weiter.
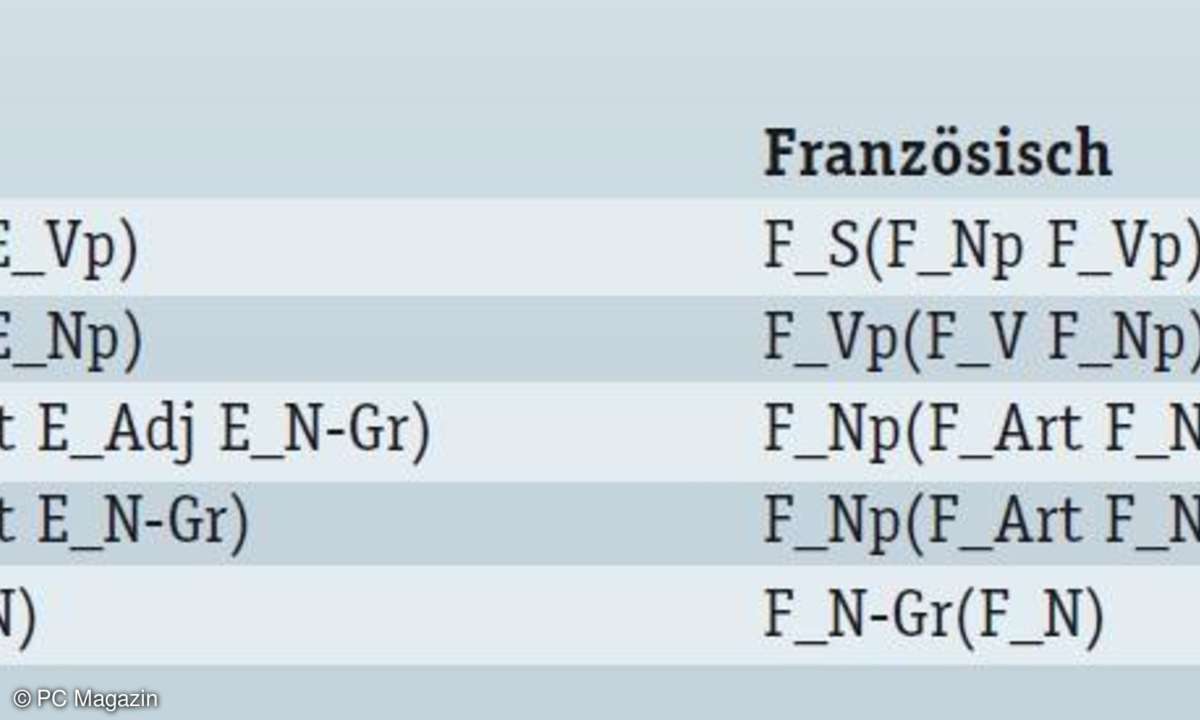
Für die Übersetzung ins Französische werden fünf Regeln plus ein Wörterbuch benötigt. Das vorangestellte "E" bzw "F" bei den Regeln steht für "Englisch" bzw. "Französisch".
filleVier der Regeln sind trivial, lediglich Regel 3 ist nicht trivial. Sie besagt, dass im Französischen das Adjektiv nachgestellt wird. Mit diesen Regeln kann aus dem englischen Satz automatisch der französische Satz generiert werden. Lediglich Wortwahl- und Morphologie-Module müssen noch ergänzt werden.












