In-Memory-Lösungen
Im Zeitalter von "Big Data" müssen Analyse-Tools immer größere Datenmengen verarbeiten, was zwangsläufig zu Performanceproblemen führt. Abhilfe verspricht das In-Memory-Konzept.

Nicht zuletzt seit SAP in das Geschäft mit In-Memory-Lösungen eingestiegen ist und mit großem Werbeaufwand eine eigene Technologie namens HANA (High Performance Analytic Appliance) anbietet, haben viele Unternehmen erkannt, dass sich im Bereich der Geschäftsanwendungen, insbeson...
Nicht zuletzt seit SAP in das Geschäft mit In-Memory-Lösungen eingestiegen ist und mit großem Werbeaufwand eine eigene Technologie namens HANA (High Performance Analytic Appliance) anbietet, haben viele Unternehmen erkannt, dass sich im Bereich der Geschäftsanwendungen, insbesondere bei analytischen Anwendungen (Business Intelligence, BI) aktuell ein Umbruch vollzieht.
Alle großen Softwarehersteller sind mittlerweile auf diesen Zug aufgesprungen. Kennzeichnend fu?r einen dynamisch wachsenden jungen Markt wie den der In-Memory-Technologie ist aber auch die Existenz und der Erfolg von kleinen Spezialanbietern. Wie nachhaltig ist dieser neue Trend? Was bringt der Einsatz von In-Memory-Werkzeugen im Bereich Business Intelligence?
Durchblick trotz Nebelkerzen
Die BI-Welt hatte u?ber viele Jahre eine vertraute Ordnung mit klar definierten Begriffen und sauber abgegrenzten Tool und Anwendungsklassen. Deren Eigenschaften, Vor- und Nachteile wurden von den meisten Beobachtern ähnlich wahrgenommen. Das Aufkommen von In- Memory-Technologie wirbelt den BI-Markt aktuell massiv durcheinander. Viele neue Begriffe und technische Ansätze, vor allem aber auch die vielen Nebelkerzen aus den Marketingabteilungen der Softwarehersteller machen den Durchblick selbst fu?r Experten schwer.
Streng genommen ist die In-Memory- Technologie alles andere als neu. Es gibt sie seit vielen Jahrzehnten. Tatsächlich ist sie sogar das bei Weitem populärste BI-Tool der Welt - Microsoft Excel - im eigentlichen Sinn ein In-Memory-Werkzeug: Die zu analysierenden Daten werden vollständig in den Arbeitsspeicher geladen und dort mit oftmals beeindruckender Geschwindigkeit bearbeitet.
IT-Strategien - Online-Meeting-Tools im Vergleich
Auch wer Excel nicht als BI-Werkzeug akzeptieren mag, wird zugeben, dass beispielsweise mit TM1 - auch heute noch eines der anerkannt besten Werkzeuge in seiner Anwendungsklasse - bereits in den 80er-Jahren ein In-Memory-Werkzeug fu?r multidimensionale OLAP-Analysen (Online Analytical Processing) auf dem Markt war.
Ein Problem namens Festplatte
Dass sich In-Memory-Ansätze in der Vergangenheit nicht breit im Markt durchsetzen konnten, lag vor allem an der Limitierung im bearbeitbaren Datenvolumen. Arbeitsspeicher war lange Zeit eine sehr kostspielige Komponente von Rechnerarchitekturen. Daten im Unternehmensmaßstab im Arbeitsspeicher halten zu wollen, wäre bis vor wenigen Jahren schlicht unbezahlbar gewesen. Aber Geld war nur ein Grund: Erst die heute u?blichen 64-Bit-Architekturen erlauben u?berhaupt das Adressieren eines entsprechend großen Speichervolumens.
Aus diesem Grund galt die Haltung großer Datenmengen innerhalb von Datenbanken oder in einem Dateiformat auf der Festplatte als unumgänglich. Entsprechend hatten manche Anbieter, die urspru?nglich die arbeitsspeicherbasierte Technologie anboten, sogar nachträglich festplattenbasierte Datenablagen einschließlich einer entsprechenden Zugriffslogik geschaffen. Die Skalierbarkeit auch fu?r große Datenmengen wurde seitdem mit Performance-Problemen erkauft, die in den meisten Fällen entweder innerhalb der Festplattenablage selbst oder im Datenzugriff und der Datenu?bertragung ihre Ursache haben.
Um u?berhaupt erträgliches Arbeiten mit großen Datenmengen zu ermöglichen, mussten sich Softwarehersteller und Anwenderunternehmen eine Vielzahl an Optimierungen und Workarounds einfallen lassen. Beispiele hierfu?r sind intelligentes Caching, spezialisierte Datenstrukturen wie OLAP-Cubes, aber vor allem Aggregate und andere Formen der redundanten Datenhaltung.
Optimierungen und Workarounds dieser Art hatten jedoch unerwu?nschte Nebeneffekte, die u?ber ein komplexes Wirkungsgefu?ge zu hohen Kosten und geringer Nutzung eines BI-Systems fu?hren. In nicht wenigen Fällen sind beziehungsweise waren diese Nebeneffekten die Ursache des Scheiterns oder des Dahinsiechens einer BI-Initiative.
IT-Strategien - Der Weg zur eigenen Cloud
Zunächst erfordern Entwicklung und Aufbau von Workarounds und die Optimierung von Datenmodellen großen Aufwand. Die Kosten hierfu?r u?bersteigen diejenigen fu?r Softwarelizenzen in der Regel erheblich. Dass vielen Unternehmen internes Know-how und die Kapazitäten fehlen, verstärkt diesen Effekt, da man sich teure Experten und Berater von außen hinzuholen muss.
Oft sind die initialen Kosten fu?r den Aufbau einer BI-Lösung aber noch gar nicht der Kern des Problems. Denn die Lösungen und Workarounds sind oft sehr komplex und kompliziert, was Betrieb und Wartung eines Systems auf Dauer sehr kostspielig machen können.
Schwerfällige Anwendungen
Komplexität und Redundanzen sorgen aber in vielen Fällen auch fu?r Qualitätsprobleme: Liegen Daten mehrfach im System vor, besteht das Risiko von Inkonsistenzen in der Datenu?bertragung. In schlecht gemachten, vor allem aber in historisch gewachsenen Lösungen sind auch Logiken fu?r die Datenverarbeitung redundant und leicht unterschiedlich implementiert. Sie werden schlicht zur Verarbeitung der an verschiedenen Stellen im System liegenden Daten mehrfach benötigt.
Eine nachträgliche Kapselung der Primär-Implementierung unterbleibt aus Zeit- und Aufwandsgru?nden, manchmal aber auch schlicht, weil diese undokumentiert und nicht allen Beteiligten bekannt ist. Auch wenn im BI-Umfeld gerne und zu Recht auf die aus den operativen Systemen ererbten Datenqualitätsprobleme verwiesen wird, tragen somit auch hausgemachte Fehler innerhalb der BI-Lösung zu einer eingeschränkten Verwendbarkeit und Verlässlichkeit der Daten bei.
Neben diesen Qualitätsproblemen ist die geringe Flexibilität eine Hauptursache fu?r die Unzufriedenheit mit BI-Lösungen. Auch dies lässt sich in vielen Fällen auf das Grundproblem der festplattenbasierten Datenablage in klassischen BI-Architekturen zuru?ckfu?hren. Datenwu?rfel, Aggregate und andere Datenstrukturen sind in den allermeisten Fällen auf vorher vereinbarte Anwendungszwecke hin optimiert.
Ändern sich die fachlichen Anforderungen, etwa durch den Bedarf der Analyse weiterer Daten, so zieht dies Erweiterungsarbeiten nach sich. Neben den Kosten hierfu?r ist oft die Geschwindigkeit, mit der diese Arbeiten erfolgen können, ein massives Problem.
Da in vielen BI-Landschaften die IT-Ressourcen bereits auf Monate verplant sind und eine zeitnahe Umsetzung von Anforderungen nicht möglich ist, werden die Fachbereiche auf diese Weise sehr häufig in Alternativlösungen gezwungen, um ihre kurzfristigen Analysebedarfe zu decken. Dieser Umstand trägt ganz wesentlich zum Wildwuchs klassischer BI-Lösungen bei, der in vielen Unternehmen zu beobachten ist.
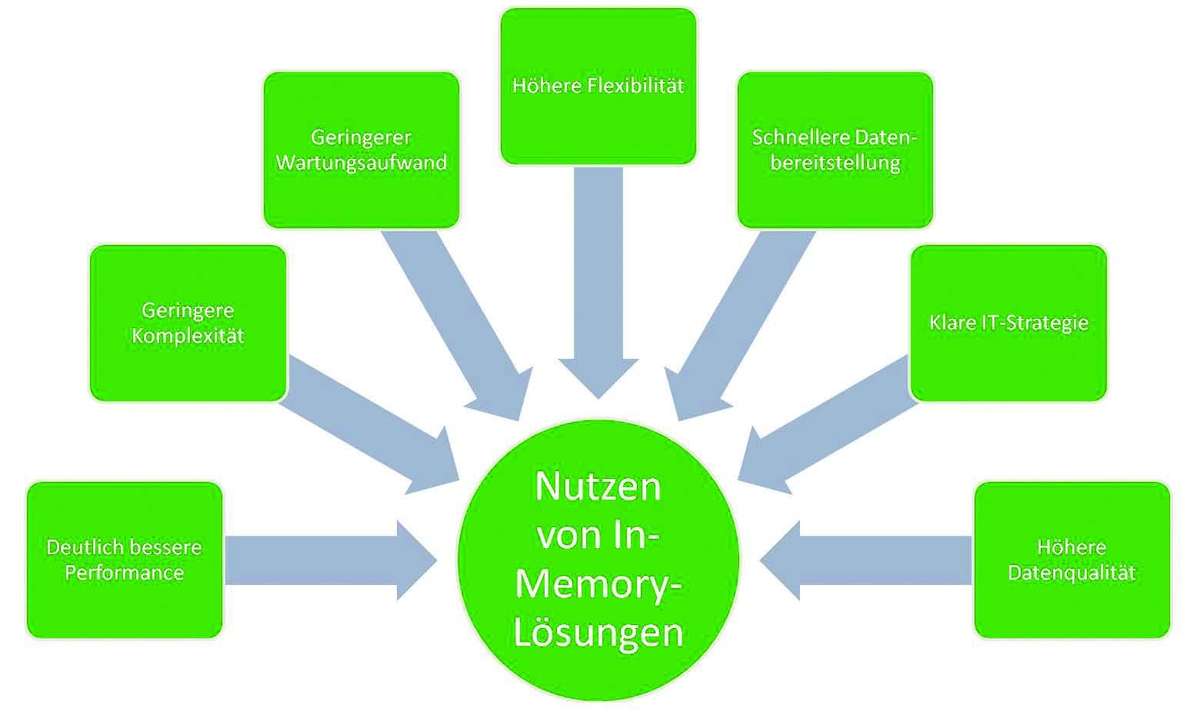
In-Memory: mehr als Performance
Einige der Grundprobleme klassischer BI-Architekturen wurzeln also in der Aufbewahrung von Daten auf Festplatten und den damit verbundenen Performance-Engpässen. An dieser Stelle anzusetzen löst somit nicht nur die Performanceprobleme, sondern bereitet auch die Basis fu?r die grundsätzliche Vereinfachung von System und Anwendungen. All die Optimierungen und Workarounds, die bisher unverzichtbar waren, um u?berhaupt mit einem System arbeiten zu können, werden durch den Einsatz von In-Memory- Architekturen u?berflu?ssig.
Letztendlich bedeutet die Einfu?hrung von In-Memory-Lösungen also weit mehr als eine hohe Performance. Sie fu?hrt vor allem auch zu einer deutlichen Kostenersparnis, einer stringenten ITStrategie und vor allem zu zufriedenen, aktiven Anwendern, die den eigentlichen Return on Investment aus Daten und Systemen erst generieren.
Auch wenn die meisten In-Memory- Lösungen im Sinne der obigen Betrachtungen letztlich eine sinnvolle Investition sein können, lohnt der Vergleich verschiedener Angebote im Bereich der In-Memory-Analytik. Schließlich sind die Technologien im Markt sehr unterschiedlich leistungsfähig. Vor allem aber bringen sie eine Vielzahl an hilfreichen, ergänzenden Features mit sich.
Der Markt bietet mittlerweile eine Vielzahl von Produkten, die den verfu?gbaren Arbeitsspeicher teilweise ganz unterschiedlich verwenden und mit anderen technologischen Kniffen verbinden. Komprimierungstechniken beispielsweise können sehr unterschiedlich ausgeprägt sein. Eine starke Kompression der Daten hilft, mit dem verfu?gbaren Arbeitsspeicher effizient umzugehen.
Unterschiedliche Ansätze
Da die meisten Lizenzmodelle u?ber das komprimierte Datenvolumen abgebildet sind, ist auch diesbezu?glich die Kompression ein ganz entscheidender Faktor. Eine starke Kompression geht aber typischerweise einher mit Einschränkungen beim Update von Daten - nicht alle Hersteller bieten geeignete Deltaverfahren - und bei der Zugriffsgeschwindigkeit fu?r bestimmte Arten von Abfragen.
Natu?rlich muss sich auch ein In-Memory- Werkzeug daran messen lassen, wie einfach sich Daten dort integrieren und organisieren lassen. Die Verfu?gbarkeit von Schnittstellen zu sozialen Netzwerken, Hadoop und anderen Big-Data-Datenquellen sollte hier beispielsweise betrachtet werden.
Auch die Modellierungswerkzeuge fu?r den Aufbau der Datenstrukturen innerhalb des In-Memory-Tools unterscheiden sich deutlich. QlikView beispielsweise ermittelt Assoziationen zwischen verschiedenen Datentabellen automatisch und macht - zumindest theoretisch - eine explizite Modellierung u?berflu?ssig. Solche Automatismen sind aber nur so gut wie die impliziten Metadaten der jeweiligen Quellen. Folglich zwingt die Verwendung von QlikView zu einer gewissen Systematik und Disziplin bei der Bereitstellung und beim Import der Daten.
Ein weiteres Unterscheidungsmerkmal fu?r In-Memory-Werkzeuge liegt in der Verfu?gbarkeit von komplexen Analyseverfahren (Data Mining, Predictive Analytics). SAS als langjähriger Marktfu?hrer in diesem Segment bietet seit einigen Monaten mit SAS High Performance Analytics eine Lösung, die umfassende Analytik auch fu?r Big Data ermöglicht.
Aber auch SAP versucht, sich in diesem Umfeld zu profilieren. SAP HANA enthält mittlerweile auch eine Reihe von Algorithmen in einer sogenannten Predictive Analytics Library. Zusätzlich besteht die Möglichkeit der Integration von R, der mittlerweile umfassendsten Data-Mining- Plattform. Nebenbei bietet R auch eine Vielzahl an Datenschnittstellen zu den wichtigsten modernen Datenquellen, allen voran sozialen Netzwerken.