Gescannte Texte bearbeiten mit gImageReader
Wäre es nicht praktisch, eingescannte Texte einfach bearbeiten zu können? Mit gImageReader ist das kein Problem. Das Bearbeitungsprogramm scannt Texte in Bildern und macht editierbaren Text daraus.

Tipp 1: Deutsche Spracherkennung installieren Achten Sie bei der Programminstallation darauf, das Häkchen für die Unterstützung internationaler Sprachen zu setzen. Da Windows 11 und 10 keinen Benutzerschreibzugriff auf Programmverzeichnisse gewähren, schalten Sie in den Einstellungen (Symbol obe...
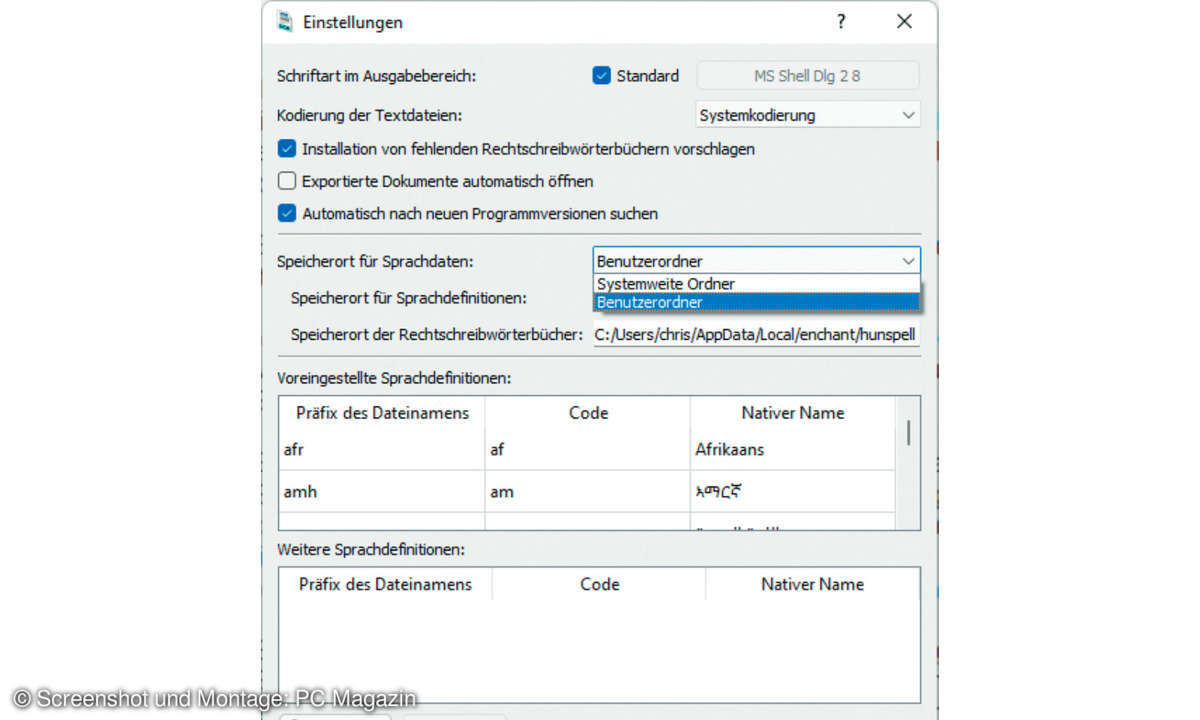
Tipp 1: Deutsche Spracherkennung installieren
Achten Sie bei der Programminstallation darauf, das Häkchen für die Unterstützung internationaler Sprachen zu setzen. Da Windows 11 und 10 keinen Benutzerschreibzugriff auf Programmverzeichnisse gewähren, schalten Sie in den Einstellungen (Symbol oben rechts) den Speicherort für Sprachdaten auf Benutzerordner um. Wählen Sie dann über das Menü neben dem Alles-erkennen-Button Sprachen verwalten. Wählen Sie Deutsch.
Tipp 2: Gescannte Dokumente importieren
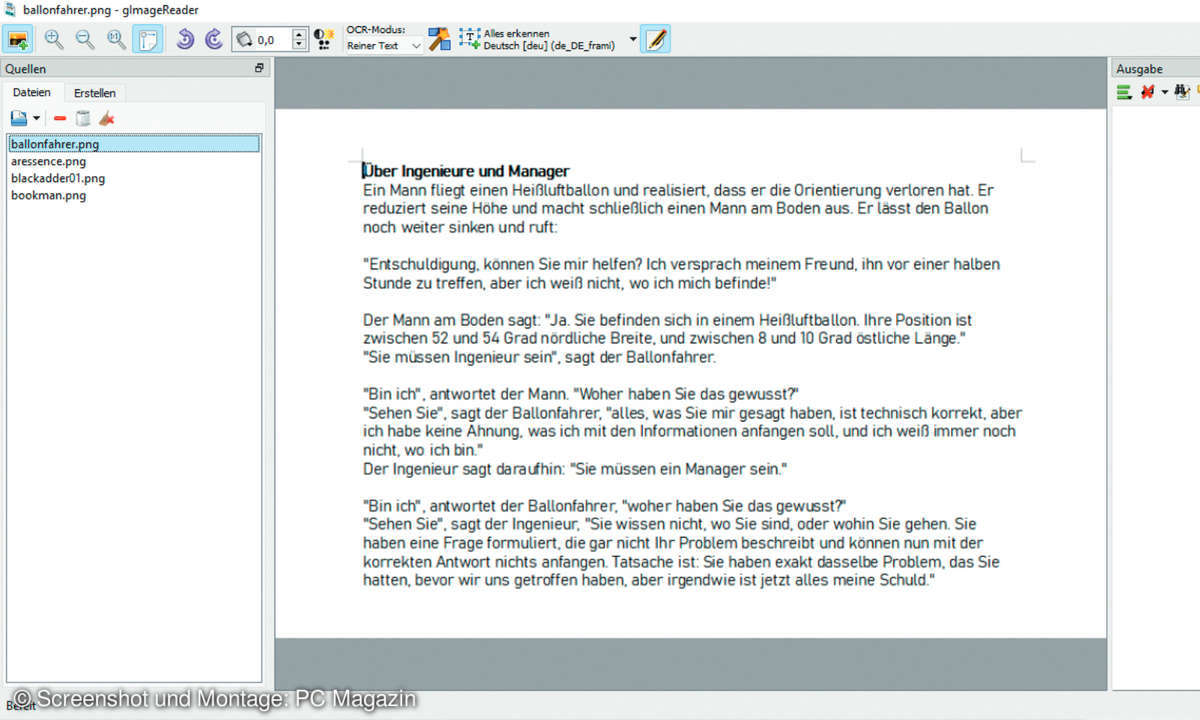
Die Benutzeroberfläche von gImageReader ist an manchen Stellen etwas anders als von Windows gewöhnt. Klicken Sie im Feld Quellen auf Bilder hinzufügen, um gescannte Bild- oder PDF-Dateien zu importieren. Auf diese Weise können auch mehrere Dokumente automatisch hintereinander eingelesen werden. Auf der Registerkarte Erstellen kann direkt ein Scanner genutzt werden, um Dokumente auf Papier einzulesen.
Tipp 3: Erkennung verbessern
Für eine bestmögliche Texterkennung sollten Sie die Dokumente kontraststark und rechtwinkelig scannen. Eine klare und einheitliche Druckschrift verbessert die Erkennung. Die im gImageReader verwendete Tesseract-Engine erkennt aber auch einige Schnörkelschriften und alte Schreibmaschinentypen.
Schräg gescannte Dokumente lassen sich mit dem Zahlenfeld Rotationsmodus in kleinen Schritten in die Horizontale drehen, was die Erkennungsqualität deutlich verbessert. Das Symbol Bildbearbeitung blendet Werkzeuge ein, um Helligkeit, Kontrast und Auflösung des Bildes einzustellen. Hier ist Ausprobieren angesagt, um die bestmögliche Erkennung zu erreichen
Tipp 4: Text erkennen und Fehler korrigieren
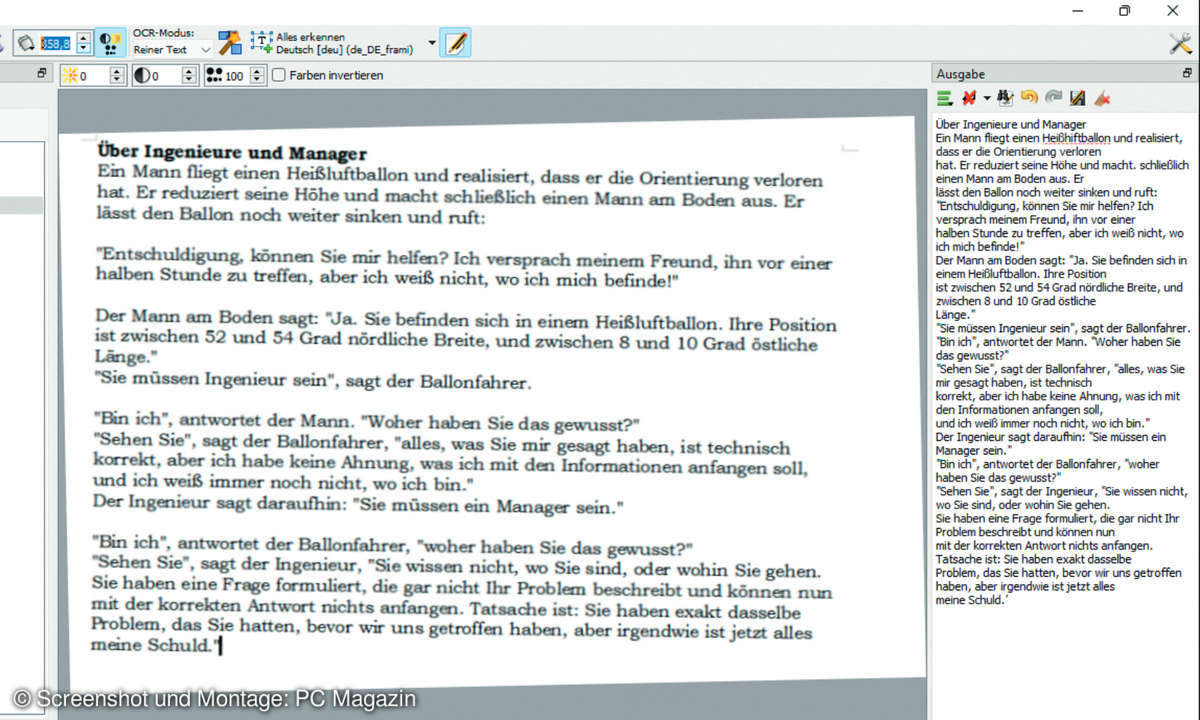
Bei einfachen gescannten Texten funktioniert Alles erkennen gut. Enthält das Dokument aber Bilder oder Textkästen, nehmen Sie die Funktion Layout automatisch erkennen. Damit werden Textbereiche markiert und Bilder ignoriert. Alternativ ziehen Sie rechteckige Bereiche auf, die nacheinander gelesen werden.
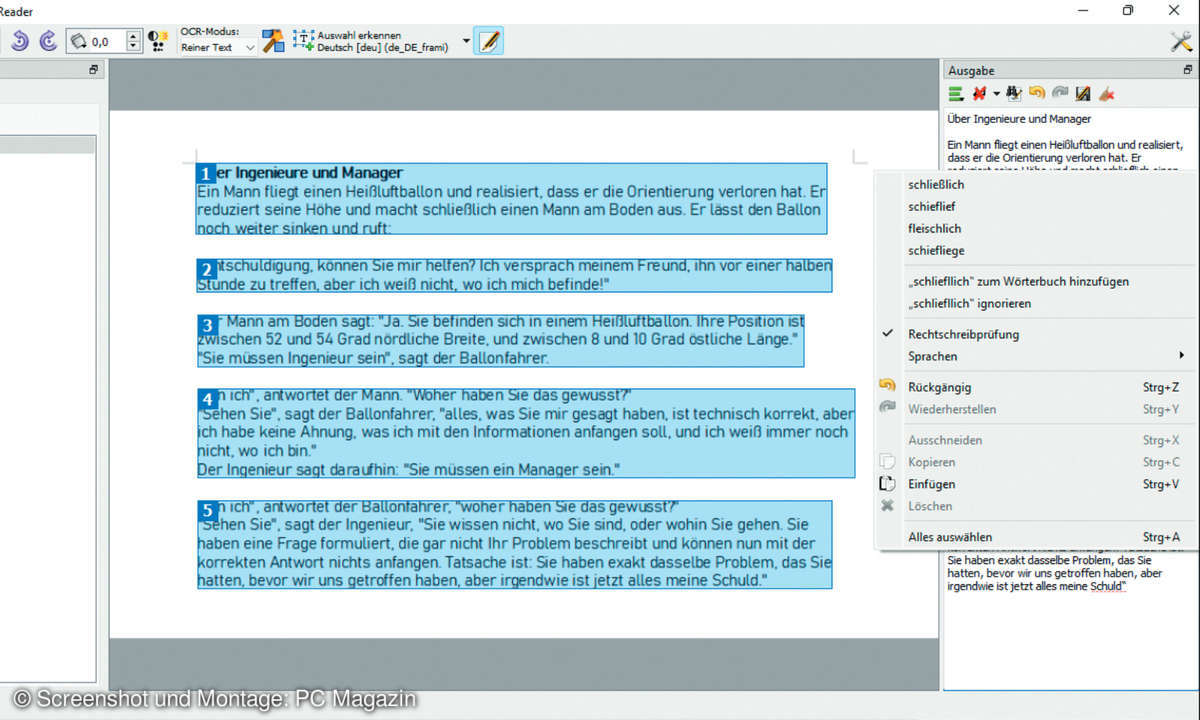
In der Spalte Ausgabe legen Sie fest, ob weitere erkannte Texte automatisch an den bestehenden Text angehängt werden oder diesen ersetzen. Der erkannte Text wird rechts im Fenster angezeigt. Wörter, die nicht im mitgelieferten Wörterbuch stehen, werden wie in Word rot unterkringelt. Korrigieren Sie die Wörter per Kontextmenü. Das bedeutet aber nicht, dass der komplette, nicht markierte Text fehlerfrei erkannt wurde. Also immer nochmal lesen.