Data-Mining-Methoden
- Informationsschätze entdecken mit Data Mining
- Data-Mining-Methoden
- Klassifikationsverfahren
- Regressionsanalyse
Assoziationsanalyse ...
Assoziationsanalyse
Data-Mining-Methoden entstammen im Wesentlichen der Statistik, dem maschinellen Lernen und der künstlichen Intelligenz. Die Methoden im Einzelnen sind als solche nicht neu, sondern wurden teilweise schon vor Jahrzehnten entwickelt. Allerdings waren sie bis vor einigen Jahren überwiegend in einem eher naturwissenschaftlich geprägten Umfeld im Einsatz. Haupteinsatzgebiet heute sind Wirtschaft und E-Business.
Ein häufig eingesetztes Data-Mining-Verfahren ist die Assoziationsanalyse mittels Regelinduktion. Durch maschinelles Lernen wird dabei versucht, aus den Daten Wenn-dann-Regeln zu generieren, die beschreiben, welche Gruppen von Objekten oder Eigenschaften häufig gemeinsam auftreten. "Wer in der IT-Branche tätig ist, verfügt häufig (zu über 70 Prozent) über ein Jahres-Bruttoeinkommen über 40 000 Euro" wäre eine solche Regel, die ein Data-Mining-Tool entdecken könnte.
Assoziationsregeln werden durch Support- und Konfidenzwerte bewertet. Der Supportwert ist die Maßzahl dafür, wie viele Datensätze im Verhältnis zu den Gesamtdaten diese Regel unterstützen - im Beispiel oben 70. Er gibt also Auskunft über die Stärke des Zusammenhangs. 100 Prozent wäre ein deterministischer, 10 Prozent ein schwacher Zusammenhang. Im ersten Fall gilt die Regel immer, im letzten Fall nur in 10 Prozent.
Der zweite wichtige Wert, der Konfidenzwert, sagt aus, wie viele Datensätze diese Regel unterstützen, im Verhältnis zu den Datensätzen, die nur die Prämisse der Regel supporten.
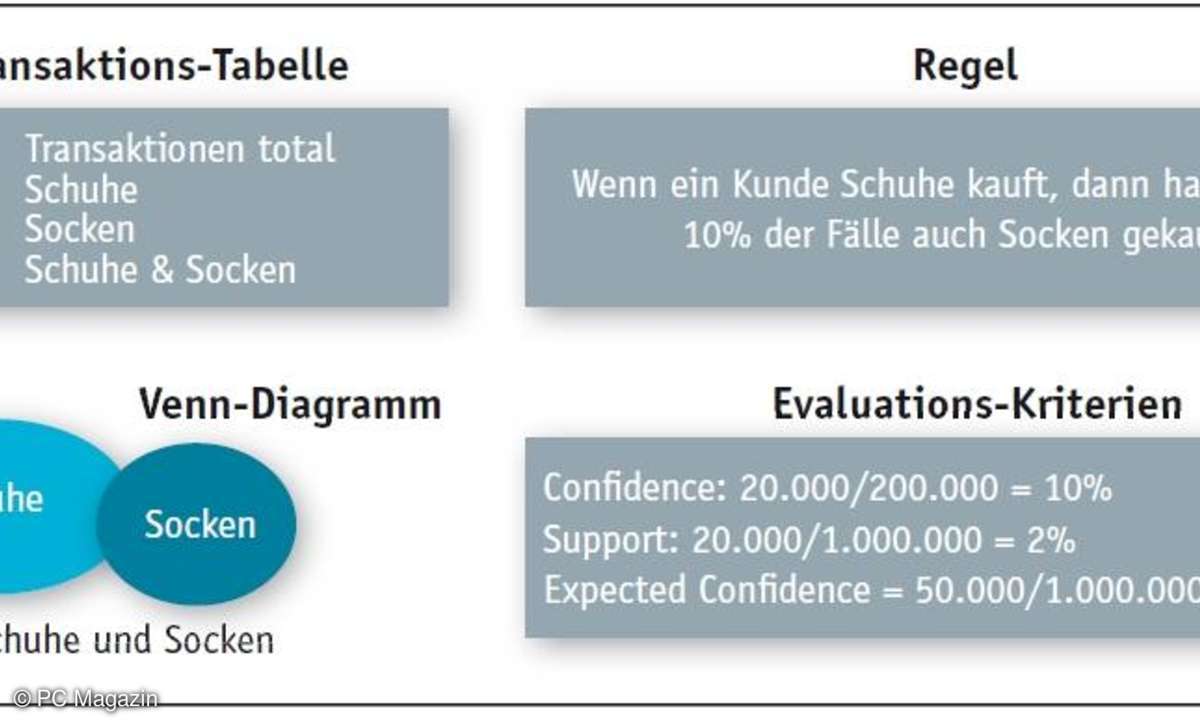
Betrachten wir die Regel: "Wenn ein Kunde Schuhe kauft, dann hat er in 10 Prozent der Fälle auch Socken gekauft." Der Wenn-Teil mit den Schuhen bildet den so genannten Regelkopf beziehungsweise die Prämisse, der Dann-Teil mit den Socken ist der Regelrumpf beziehungsweise die Konklusion.
Das Beispiel in der Grafik auf der nächsten Seite oben enthält einige Zahlen, die die Berechnung von Supportund Konfidenz illustrieren: Nach der Transaktionstabelle haben 200 000 Personen Schuhe und 50 000 Socken gekauft. Die Schnittmenge, also diejenigen, die Schuhe und Socken gekauft haben, bilden 20 000 Käufer.
Die Konfidenz einer Regel gibt Auskunft über die Stärke des Zusammenhangs zwischen Regelrumpf und Regelkopf und beträgt hier zehn Prozent. Sie wird berechnet, indem der Anteil der Transaktionen, die sowohl Schuhe als auch Socken enthalten, ins Verhältnis gesetzt wird zu allen Transaktionen, in denen Schuhe gekauft werden. Der gleichzeitige Kauf beider Produkte kommt bei zwei Prozent aller Transaktionen vor. Dieser Anteil stellt den Support der Regel dar.
Für die Assoziationsanalyse wird nun für beide Werte - Support und Konfidenz - ein Minimum definiert. Anschließend werden mittels dieser Minima alle Regeln erstellt, deren Konfidenz-bzw. Supportwerte darüber liegen. Hiermit lässt sich ein einfaches Assoziationsmodell erstellen. Dabei gilt: Je größer diese Werte, desto bedeutender ist die Regel.
Eine der häufigsten Anwendungen der Regelinduktion ist die Analyse von Warenkorbdaten. Hier wird speziell eine Menge an Warenkörben daraufhin untersucht, ob Zusammenhänge zwischen den gekauften Waren bestehen, beispielsweise: Welche Produkte haben Kunden bei einem Kauf gemeinsam erworben?
Warenkorbanalysen stellen die beste Möglichkeit bereit, das Kaufverhalten zu analysieren und Kundenbedürfnisse aufzuspüren. Hat man durch eine Warenkorbanalyse beispielsweise Gruppen von häufig zusammen verkauften Produkten herausgefunden, lässt sich das Sortiment optimieren und konsumgerecht platzieren.
Clusteranalyse
Ein anderes Data-Mining-Verfahren ist die Clusteranalyse. Die Clusteranalyse wird benützt, um einen Datenbestand zu segmentieren - also Gruppen von Datensätzen zu finden, die Ähnlichkeiten aufweisen. Die Ähnlichkeiten der Objekte innerhalb einer Kategorie sollen dabei möglichst groß, zwischen den Kategorien gering sein. Dabei können zur Clusterbildung auch mehrere Attribute gleichzeitig - etwa Alter, Größe und Gewicht - berücksichtigt werden.
Mit der Clusteranalyse lassen sich beispielsweise bestimmte Besuchergruppen identifizieren. Ein einfaches Exempel für eine in einer Kundendatenbank gefundene Gruppe könnte etwa folgendermaßen aussehen:
Gruppe-020: (N=103)
Bestellhäufigkeit = selten
durchschn-Bestellvol < 100
Alter > 45
Hier wurde eine ältere Kundengruppe mit schwacher Bestellfrequenz gefunden. Die Clusteranalyse ermöglicht es also beispielsweise, profitable und weniger profitable Kunden zu unterscheiden. Mit anderen Techniken wie neuronalen Netzen lassen sich die Analysen vertiefen und konkrete Eigenschaften finden, die diese Gruppen genauer voneinander unterscheiden. Diese Eigenschaften können zum Beispiel darüber Auskunft geben, was profitable von nicht profitablen Besuchern unterscheidet.










